Introduction
딥러닝에서는 학습을 시킬 수록 Gradient가 폭발하거나 사지하는 문제가 생기고, 특정 feature에 지나치게 쏠릴 수 있다는 문제점이 있다. 따라서 이를 적절히 해결을 해주어야 한다.
일단 데이터부터 정의해주자.
>>> import numpy as np
>>> np.random.randint(1, 9, (10,3))
array([[1, 7, 2],
[7, 1, 7],
[1, 3, 4],
[6, 7, 3],
[5, 2, 5],
[8, 1, 7],
[1, 8, 6],
[7, 1, 2],
[6, 4, 1],
[2, 3, 1]])
이걸 읽고 있을 정도라면 왜 미니배치가 필요한지는 알고 있어야 한다. 모른다면 설명을 하자. 미니배치를 안 한다면 저 3개의 feature을 가진 10개의 데이터를 한 프로세서에서 처리하게 된다. 기본적으로 병렬 연산이 기본인 GPU를 낭비하는 것이고, CPU라고 해도 멀티코어를 소용 없게 하는 행위이다. 메모리가 절약되는 것도 좋다. 10개의 데이터에서 epoch 1번당 10번을 학습하는 것이다. 하지만, 배치 크기가 2라면 5번을 학습해 2배를 줄일 수 있다.
학습의 측면에서도 이점이 있다. 이에 대해서는 카카오 브레인 블로그의 설명을 보자.
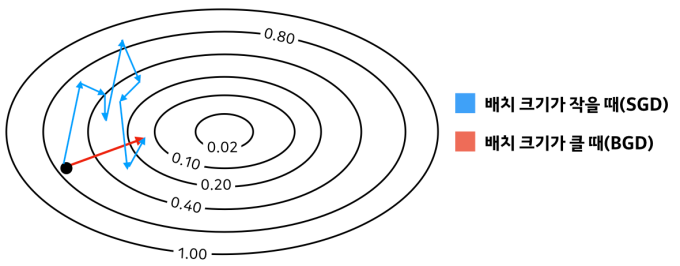 이렇다는 것이 알려져 있다. 물론 이에 대한 반박도 충분히 있다. 이것도 위의 블로그에서 보면 된다.
이렇다는 것이 알려져 있다. 물론 이에 대한 반박도 충분히 있다. 이것도 위의 블로그에서 보면 된다.
- Batch를 고려할 때의 코드
>>> import numpy as np
>>> x = np.random.randint(1, 9, (10, 3))
>>> batch_size = 2
>>> x_train = x.reshape(-1, batch_size, 3)
>>> x_train
array([[[8, 5, 5],
[6, 1, 1]],
[[6, 7, 6],
[4, 5, 1]],
[[8, 4, 8],
[7, 5, 3]],
[[8, 7, 6],
[5, 8, 1]],
[[8, 3, 4],
[5, 6, 1]]])
Batch Normalization
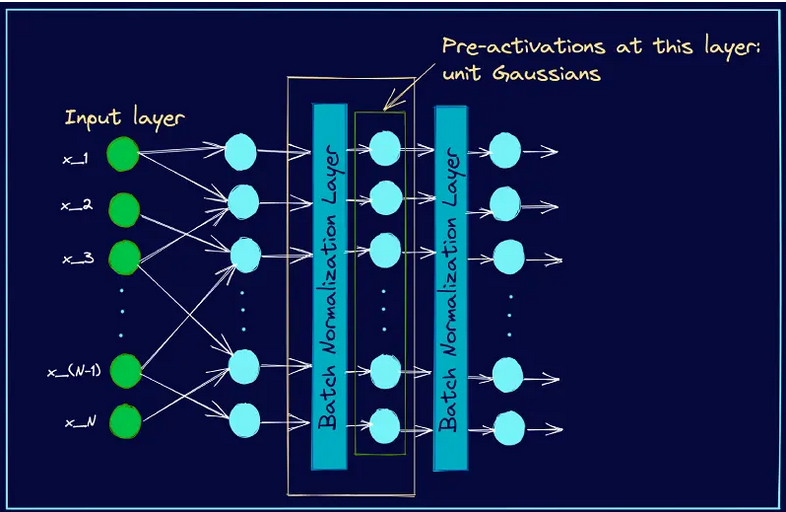 이미지 출처: pinecone blog
대충 이런 Batch Normalization Layer가 있다고 한다.
이미지 출처: pinecone blog
대충 이런 Batch Normalization Layer가 있다고 한다.
정말 Batch Normalization을 하는 층이니 그냥 보자.
우선 배치 하나마다 각 feature의 평균과 표준 편차를 구해준다. (수식은 나중에 보자)
 이미지 출처: pinecone blog
그런 다음 다음과 같은 식을 적용해준다.
$$
\huge{\hat x_{i}= \frac{x_{i}-\mu_{\text{batch}}}{\sqrt{\sigma_{\text{batch}}^2+\epsilon}}}
$$
$\mu$는 평균이고, $\sigma$는 표준 편차이며, 엡실론은 division by zero를 피하기 위해 넣어준다.
이미지 출처: pinecone blog
그런 다음 다음과 같은 식을 적용해준다.
$$
\huge{\hat x_{i}= \frac{x_{i}-\mu_{\text{batch}}}{\sqrt{\sigma_{\text{batch}}^2+\epsilon}}}
$$
$\mu$는 평균이고, $\sigma$는 표준 편차이며, 엡실론은 division by zero를 피하기 위해 넣어준다.
이를 코드로 보자. 채널은 고려하지 않았다.
>>> import numpy as np
>>> data_size = 10
>>> data_features = 3
>>> x = np.random.randint(1, 9, (data_size, data_features))
>>> batch_size = 2
>>> x_batches = x.reshape(-1, batch_size, data_features)
>>> x
array([[3, 1, 5],
[6, 4, 7],
[4, 2, 8],
[3, 3, 4],
[8, 5, 2],
[5, 1, 2],
[2, 3, 8],
[8, 4, 8],
[1, 6, 7],
[1, 4, 2]])
>>> x_batches
array([[[3, 1, 5],
[6, 4, 7]],
[[4, 2, 8],
[3, 3, 4]],
[[8, 5, 2],
[5, 1, 2]],
[[2, 3, 8],
[8, 4, 8]],
[[1, 6, 7],
[1, 4, 2]]])
>>> x_batch_mean = np.mean(x_batches, axis=1, keepdims=True)
>>> x_batch_mean
array([[4.5, 2.5, 6. ],
[3.5, 2.5, 6. ],
[6.5, 3. , 2. ],
[5. , 3.5, 8. ],
[1. , 5. , 4.5]])
>>> x_batch_var = np.var(x_batches, axis=1, keepdims=True)
>>> eps = 1e-8
>>> x_batch_norm = (x_batches - x_batch_mean) / (x_batch_var + eps)
>>> x_batch_norm
array([[[-0.66666666, -0.66666666, -0.99999999],
[ 0.66666666, 0.66666666, 0.99999999]],
[[ 1.99999992, -1.99999992, 0.5 ],
[-1.99999992, 1.99999992, -0.5 ]],
[[ 0.66666666, 0.5 , 0. ],
[-0.66666666, -0.5 , 0. ]],
[[-0.33333333, -1.99999992, 0. ],
[ 0.33333333, 1.99999992, 0. ]],
[[ 0. , 0.99999999, 0.4 ],
[ 0. , -0.99999999, -0.4 ]]])
배치 정규화가 안 끝났다. $$ y_{i}= \mathcal{BN}(x_{i)}= \underbrace{\mathbf{\gamma} \cdot \hat x_{i}}_{\text{내적}} + \mathbf{\beta} $$ 말인 즉슨 저 둘은 벡터였다는 소리다. 정확히는 파라미터라고 할 수 있다.
Layer Normalization
우선 Layer Normalization은 feature들의 평균과 표준 편차를 구한다. Batch? 크게 신경 안 쓴다. 이렇게 하면 특정 feature에 의존하지 않는 등 장점이 있는 것이 알려져 있다.
$$
\huge{\hat x_{i}= \frac{x_{i}-\mu_{\text{layer}}}{\sqrt{\sigma_{\text{layer}}^2+\epsilon}}}
$$
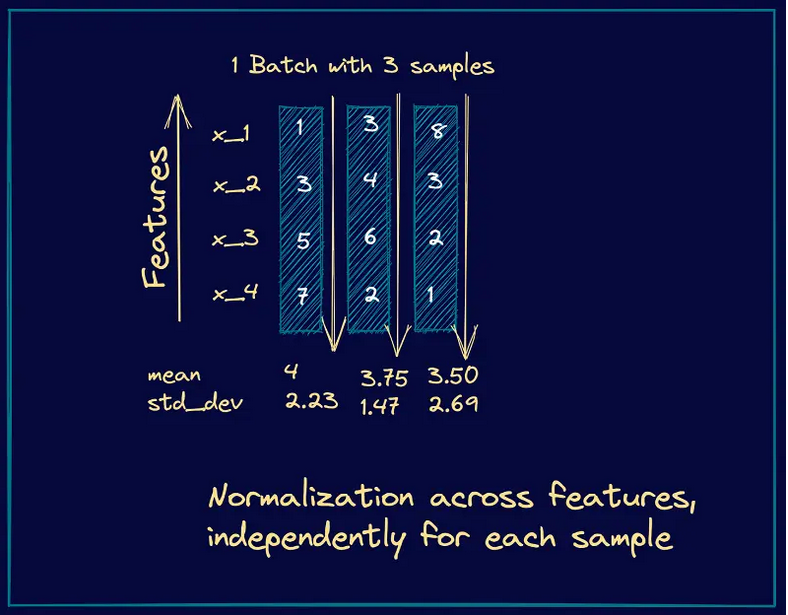
코드로 보자.
>>> import numpy as np
>>> data_size = 10
>>> data_features = 3
>>> x = np.random.randint(1, 9, (data_size, data_features))
>>> batch_size = 2
>>> x_batches = x.reshape(-1, batch_size, data_features)
>>> eps = 1e-8
>>> x
array([[3, 1, 5],
[6, 4, 7],
[4, 2, 8],
[3, 3, 4],
[8, 5, 2],
[5, 1, 2],
[2, 3, 8],
[8, 4, 8],
[1, 6, 7],
[1, 4, 2]])
>>> x_batches
array([[[3, 1, 5],
[6, 4, 7]],
[[4, 2, 8],
[3, 3, 4]],
[[8, 5, 2],
[5, 1, 2]],
[[2, 3, 8],
[8, 4, 8]],
[[1, 6, 7],
[1, 4, 2]]])
>>> x_layer_mean = np.mean(x_batches, axis=2, keepdims=True)
>>> x_layer_mean
array([[[3. ],
[5.66666667]],
[[4.66666667],
[3.33333333]],
[[5. ],
[2.66666667]],
[[4.33333333],
[6.66666667]],
[[4.66666667],
[2.33333333]]])
>>> x_layer_var = np.var(x_batches, axis=2, keepdims=True)
>>> x_layer_var
array([[[2.66666667],
[1.55555556]],
[[6.22222222],
[0.22222222]],
[[6. ],
[2.88888889]],
[[6.88888889],
[3.55555556]],
[[6.88888889],
[1.55555556]]])
>>> x_layer_norm = (x_batches - x_layer_mean) / (x_layer_var + eps)
>>> x_layer_norm
array([[[ 0. , -0.75 , 0.75 ],
[ 0.21428571, -1.07142856, 0.85714285]],
[[-0.10714286, -0.42857143, 0.53571428],
[-1.49999993, -1.49999993, 2.99999987]],
[[ 0.5 , 0. , -0.5 ],
[ 0.8076923 , -0.57692307, -0.23076923]],
[[-0.33870968, -0.19354839, 0.53225806],
[ 0.375 , -0.75 , 0.375 ]],
[[-0.53225806, 0.19354839, 0.33870968],
[-0.85714285, 1.07142856, -0.21428571]]])