머신 러닝 워크플로우
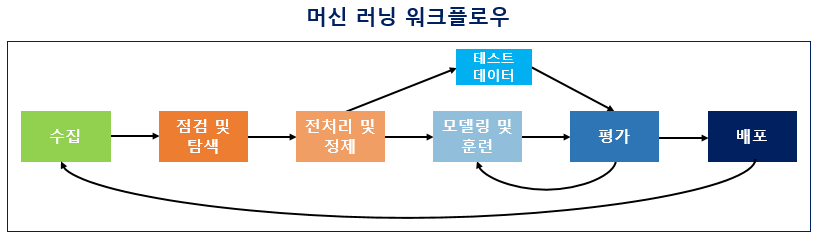
수집 (Acquisition)
머신 러닝을 위해서는 기계에 학습시켜야 할 데이터가 필요하다. 가장 기본적이지만 가장 핵심적인 부분이기도 하다.
점검 및 탐색(Inspection and exploration)
통칭 EDA라고 한다. 독립 변수, 종속 변수, 변수 유형, 변수의 데이터 타입 등을 점검하는 것이다. 말인즉슨, matplotlib을 굉장히 열심히 사용하여야 한다는 뜻이기도 하다.
전처리 및 정제(Preprocessing and Cleaning)
문자 그대로 데이터 전처리이다. 결측치에 대한 imputing을 하는 것도 전처리이고, 토큰화, 정제, 정규화, 불용어 제거 등도 다 전처리이다.
이걸 전문적으로 하는 사람을 데이터 엔지니어라고 한다.
모델링 및 훈련(Modeling and Training)
문자 그대로 데이터를 훈련하는 단계이다. 이때, 데이터를 이상적으로는 Train/Test/Validation으로 나누는 것이 좋고, 그게 잘 안 되겠다면 Train/Test로라도 나누는 것이 좋다.
왜 이걸 나누는가?
Setting Hyperparameters

- Idea #1: 데이터에 대해 잘 학습되는 하이퍼파라미터를 고르자
- BAD: KNN에서 K=1하면 트레이닝 데이터는 당연히 다 잘 되지 않을까? 근데 이렇게 분류기를 만들면 의미가 있을까?

- Idea #2: 데이터를 훈련(Train) 데이터셋과 테스트(Test) 데이터셋으로 나누고, 훈련 데이터셋으로 학습을 시켰는데 테스트 데이터셋에 가장 잘 작동하는 하이퍼파라미터를 고른다.
- BAD: 새로운 데이터에 어떻게 작동할지 잘 모름
- 이거 필드에서 쓰기 어려운 것 인정하는데 이 방법이 틀린 건 알고 넘어가야 한다.

- Idea #3: 데이터를 훈련(Train) 데이터셋과 검증(Validation) 데이터셋, 테스트(Test) 데이터셋으로 나눈 다음, 검증 데이터셋에서 가장 잘 작동하는 하이퍼 파라미터를 고른 다음, 최종적으로 test 데이터셋으로 시험하여 모델을 평가한다. 그러니까 데이터 20%가 테스트 데이터셋이라 하면 이걸 그냥 버리는 것과 다를 바가 없다!
- 실무적으로는 데이터 500개 주고 학습시키라 하는데 이걸 언제 나누고 있냐… 그래서 k-fold 출동
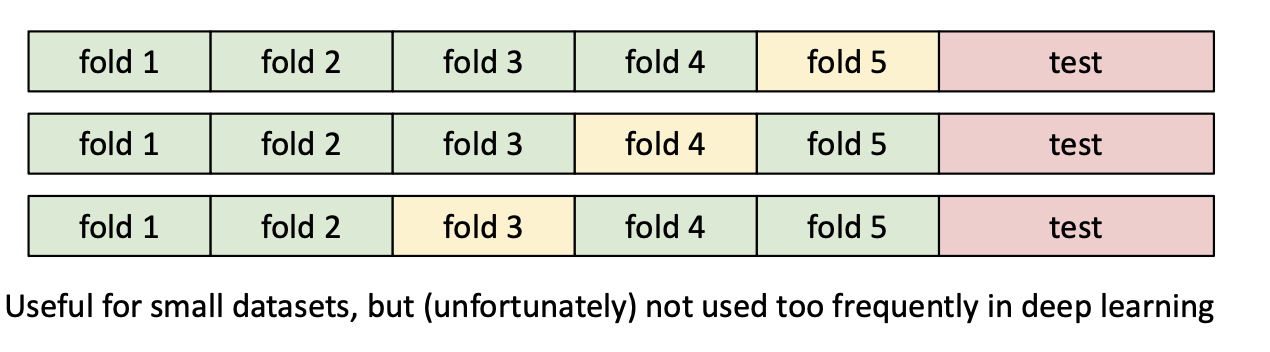
- Idea #4: Cross-Validation: 데이터를 folds로 나누고, 이걸 각자 validation으로 쓴 다음 평균값을 내서 학습한다.
Cross Validation
한 데이터를 여러 개의 Training-Validation 세트로 데이터를 나누어서 검증하는 기법. (Test는 남겨놓으쇼)
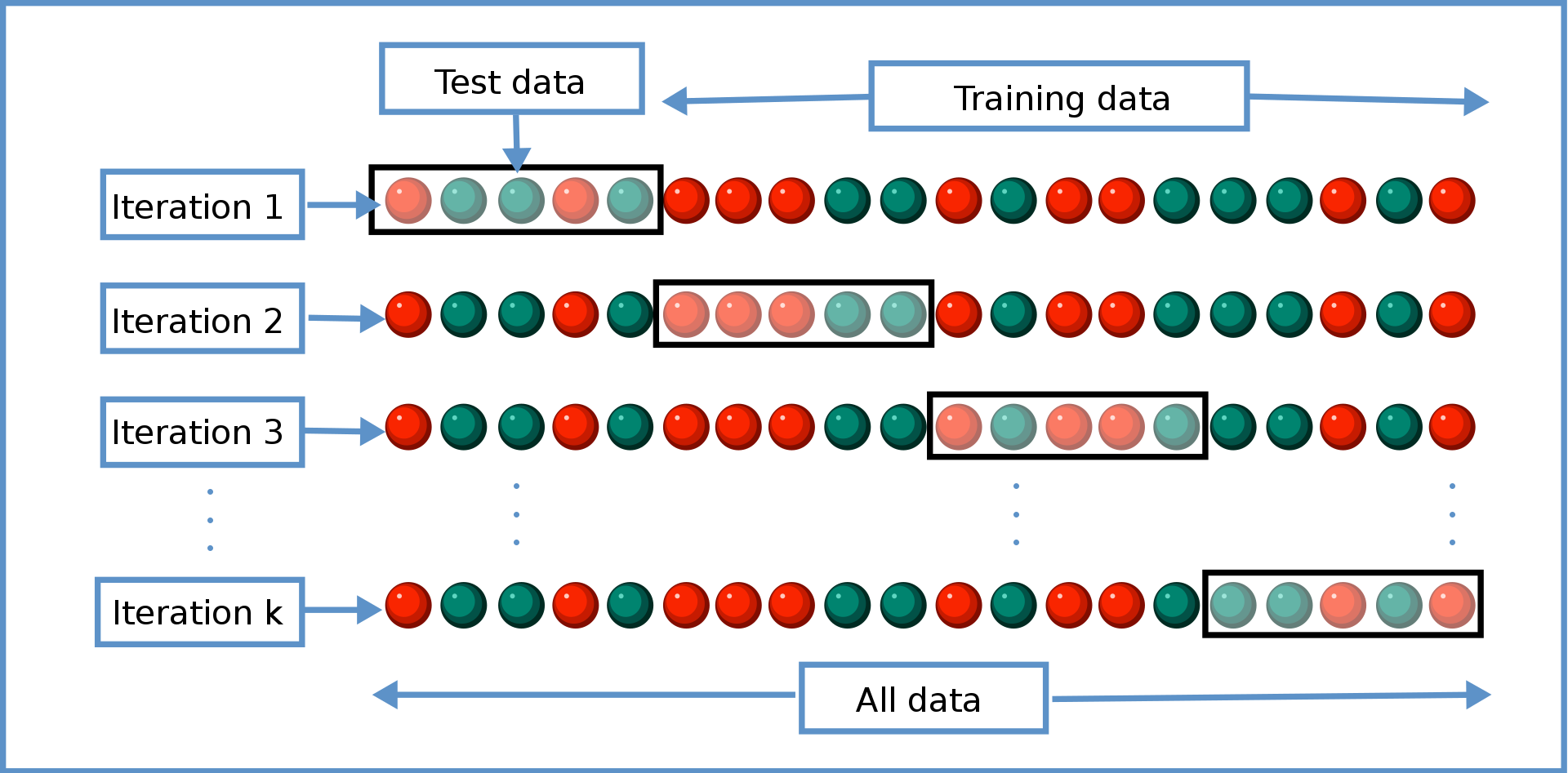 데이터를 K개로 나눈 다음, 순서대로 Test-Traning 세트으로 나누어서 검증한다.
데이터를 K개로 나눈 다음, 순서대로 Test-Traning 세트으로 나누어서 검증한다.
Stratified K-folds Cross Validation
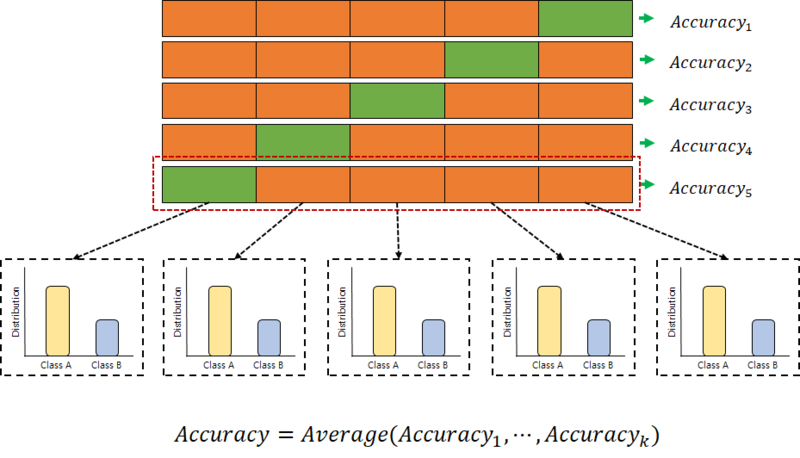 데이터를 K개로 나눈 다음, 각각의 데이터의 분포를 유지하면서 순서대로 Test-Traning 세트로 나누어서 검증한다.
데이터를 K개로 나눈 다음, 각각의 데이터의 분포를 유지하면서 순서대로 Test-Traning 세트로 나누어서 검증한다.
이렇게 하면 데이터가 적을 때 모델의 성능을 평가할 수도 있고, 교차 검증 자체의 신뢰성도 있으며, 오버피팅을 방지할 수 있다.